(将一年之前解决的问题再梳理下)
背景知识
Glance是OpenStack中管理镜像的服务,主要用于上传和下载镜像文件,后端接各种存储服务。例如Ceph、sheepdog、本地磁盘等等,大致的逻辑如图。
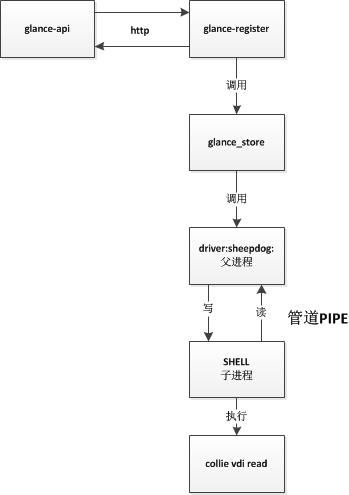
在用sheepdog作为存储后端的时候,发现下载速度非常慢只有10~20Mb/s,一般应该能够打满内网的千兆网卡达到100+Mb/s才对。在一番探究下终于找到问题所在。原来是oslo_concurrency与evenlet库不太匹配,导致数据在上图的管道中传输很慢造成的。
简单的例子
为了去除glance服务其他代码的描述,可以将问题简化为使用oslo_concurrency下载本地文件,实验代码如下。
|
|
分别执行[1][2]以及优化后的代码[3]
|
|
可以看到使用eventlet后速率降低到原来的1/6~1/7。优化代码后依旧使用eventlet,效率与不使用eventlet时基本持平,性能没有损耗。
在分析代码之前需要牢记一点。因为使用eventlet会导致相关模块都会被patch成eventlet对应的模块。而evenlet中对应模块的类又会继承原始Python模块中的类。所以,如果查看相关类的方法时,需先从eventlet对应的模块中的类中查找;如果找不到则到Python原始模块中查找。例如subprocess模块。
|
|
下面回过头重新梳理glance中拉取数据的代码逻辑。
subprocess惹的祸
oslo_concurrency使用了subprocess中的Popen类并且通过其中的communicate方法来进行管道的通信。大致逻辑如下
|
|
通过之前eventlet中的subprocess的Popen类的代码,我们知道communicate是原始subprocess的communicate方法。
|
|
由于self.stout已经被eventlet封装成了GreenPip,因此其read方法需要查看GreenPipe。通过GreenPipe的初始化可以看到,传进来的原始的管道文件封装成了_SocketDuckForFd。而GreenPipe本身继承_fileobjec,其read方法也继承_fileobject。
|
|
最终调用的是os.read。这个逻辑比较复杂,可以归纳为基本的调用过程。
|
|
这里面的关键在于select和os也会被eventlet替换,实际调用的是eventlet中的select和os。os.read中的读大小已经固定成1024(glance_store中传入的参数没有作用了),而select.select会将后续的请求提交给eventlet的Hub中心进行epoll,所以逻辑演变成
|
|
每读取1024就将请求提交给Hub进行epoll,epoll发现管道中有读事件,则再次读取1024。这个循环读取1024和提交epoll请求消耗了大量的时间。
验证逻辑
通过在data = os.read(self.stdout.fileno(), 1024)下面打印日志验证该逻辑。
|
|
|
|
结果证明select确实被替换成eventlet中的select;进行了大量的1024读取,假设读取1G的数据那么这个循环会高达100多万次(1024*1024)。
优化程序
进行大量循环1024读取是耗时的根本原因,因此增加每次读取的数据量,减少循环就会优化性能[3]。
|
|
这个就是最开始的[3]性能优化后的程序,确实提高了数据读取速率。
给glance打补丁
因为_communicate_with_select是Python的原始库的代码,因此不能直接修改。但是我们可以效仿eventlet给其打补丁。
|
|
通过打补丁,glance的下载镜像速度能够打满千兆网卡到达100+M/s,是原来的5~10倍。