requests: HTTP for humans
requests以简洁、human-friendly著称,谁用谁知道。本文从源码角度剖析requests,先从数据结构入手,再到整个HTTP访问流程,然后着重讲解requests中用于处理netrc、redirects、cache等用到的技术。
requests的数据结构图
先来个最简单的使用例子:
|
|
为了便于探寻requests中的数据结构再稍微复杂点:
|
|
实例化一个Session,然后访问多次,因此可以让requests本身进行缓存等操作,其对应的总体结构图如下:
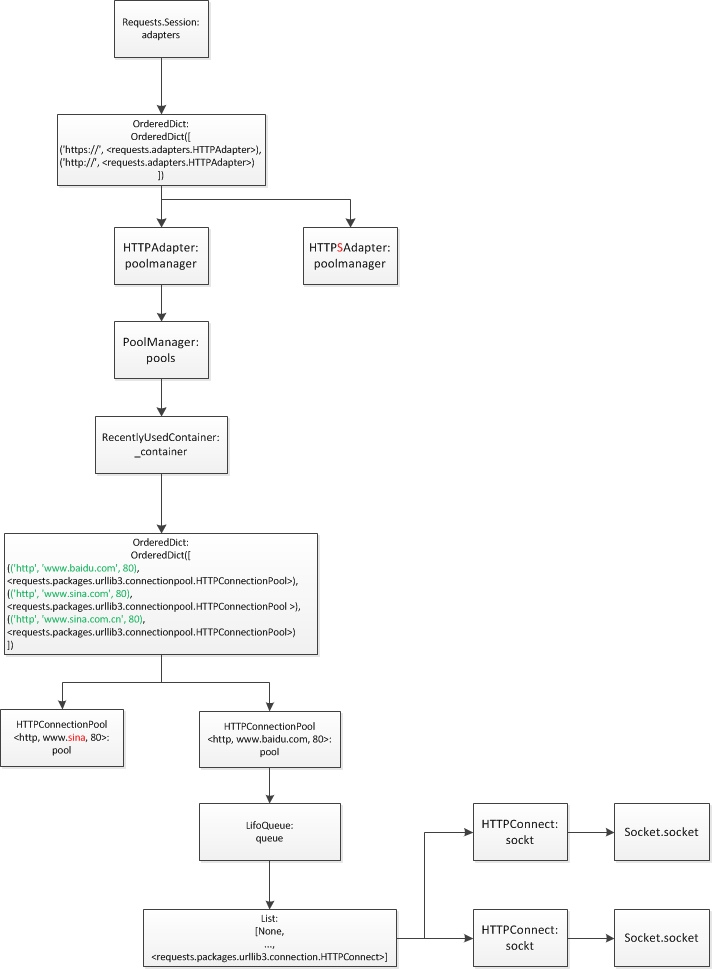
requests使用了2层缓存技术:
第一层
poolmanager缓存HTTPConnectionPool。poolmanager缓存多个链接池,以(scheme, host, port)作为key。该缓存是一个RecentlyUsedContainer(底层使用的OrderedDict),当需要缓存的缓存池过多时淘汰最老的HTTPConnectionPool。最大缓存数量可以通过参数pool_maxsize设定,默认为requests.adapters.DEFAULT_POOLSIZE10个。另外这也是第二层缓存中默认的最大缓存链接的个数。第二层
HTTPConnectionPool缓存HTTPConnection。HTTPConnectionPool缓存多个链接。该缓存底层使用LifoQueue后入先出队列,尽量重复使用同一个链接。最大的缓存数量默认也是10个。不过有一个特殊的参数block需要注意,当其为True时HTTPConnectionPool对同一个(scheme, host, port)的访问建立的最多链接数量即为最大缓存数量,获取链接时需要堵塞等待空闲的链接。
requests的操作流程
我们从最简单的get操作入手,看一看整个流程是如何完成的,其流程图如下
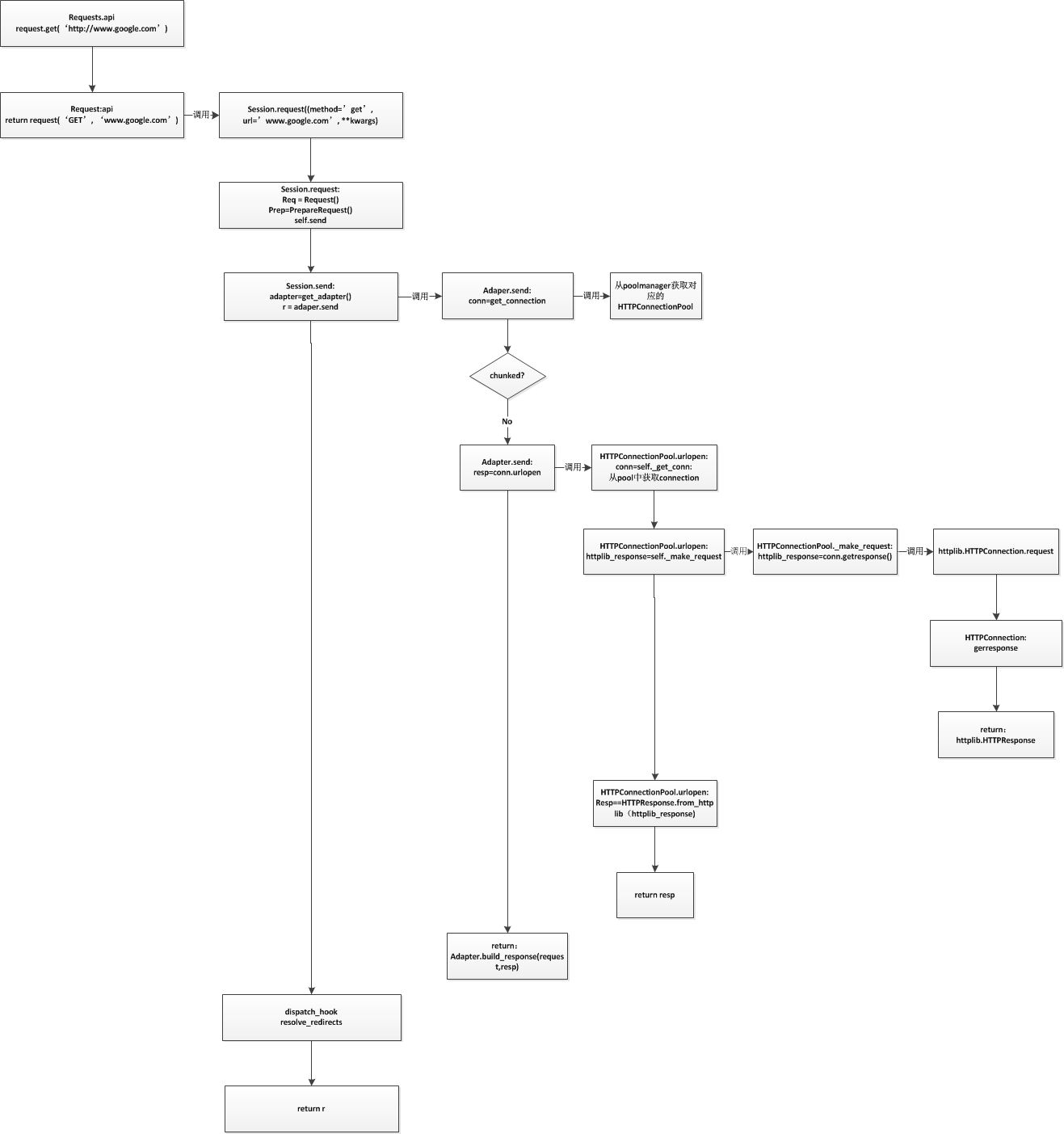
流程中需要注意,对于每层函数来说其中的conn都指的是下层数据结构(实例)。HTTPAdapter中的conn对应的数据结构是HTTPConnectionPool;HTTPConnectionPool中的conn是HTTPConnection;HTTPCOnnection中的conn是socket。