Python的Set容器
set与List对象相似,均为可变异构容器。但是其实现却和Dict类似,均为哈希表。具体的数据结构代码如下。
|
|
setentry是哈希表中的元素,记录插入元素的哈希值以及对应的Python对象。PySetObject是哈希表的具体结构:
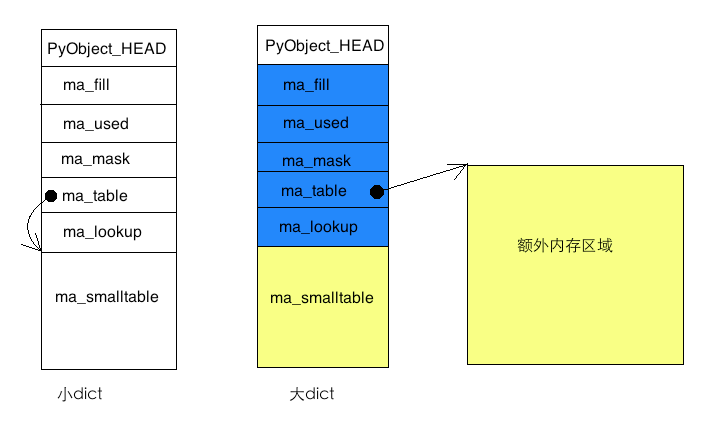
fill被填充的键的个数,包括Active和dummy,稍后解释具体意思used被填充的键中有效的个数,即集合中的元素个数mask哈希表的长度的掩码,数值为容量值减一table存放元素的数组的指针smalltable默认的存放元素的数组
当元素较少时,所有元素只存放在smalltable数组中,此时table指向smalltable。当元素增多,会从新分配内存存放所有的元素,此时smalltable没有用,table指向新分配的内存。
哈希表中的元素有三种状态:
- active 元素有效,此时setentry.key != null && != dummy
- dummy 元素无效key=dummy,此插槽(slot)存放的元素已经被删除
- NULL 无元素,此插槽从来没有被使用过
dummy是为了表明当前位置存放过元素,需要继续查找。假设a和b元素具有相同的哈希值,所以b只能放在冲撞函数指向的第二个位置。先删除a,再去查找b。如果a被设置为NULL,那么无法确定b是不存在还是应该继续探查第二个位置,所以a只能被设置为dummy。查找b的过程中,第一个位置为dummy所以继续探查,直到找到b;或者直到NULL,证明b确实不存在。
Set中的缓存
set中会存在缓存系统,缓存数量为80个_setobject结构。
|
|
freelist缓存只会对_setobject结构本身起效,会释放掉额外分配的存储键的内存。
Set中查找元素
set中元素查找有两个函数,在默认情况下的查找函数为set_lookkey_string。当发现查找的元素不是string类型时,会将对应的lookup函数设置为set_lookkey,然后调用该函数。
|
|
查找函数最后返回的插槽有三种情况:
- key存在,返回此插槽
- key不存在,对应的插槽为NULL,返回此插槽
- key不存在,对应的插槽有dummy,返回第一个dummy的插槽
set_lookkey与此类似,只不过比较元素时需要调用对应的比较函数。
set的重新散列
为了减少哈希冲撞,当哈希表中的元素数量太多时需要扩大桶的长度以减少冲撞。Python中当填充的元素大于总的2/3时开始重新散列,会重新分配一个有效元素个数的两倍或者四倍的新的散列表。
|
|
(完)