requests中的重试
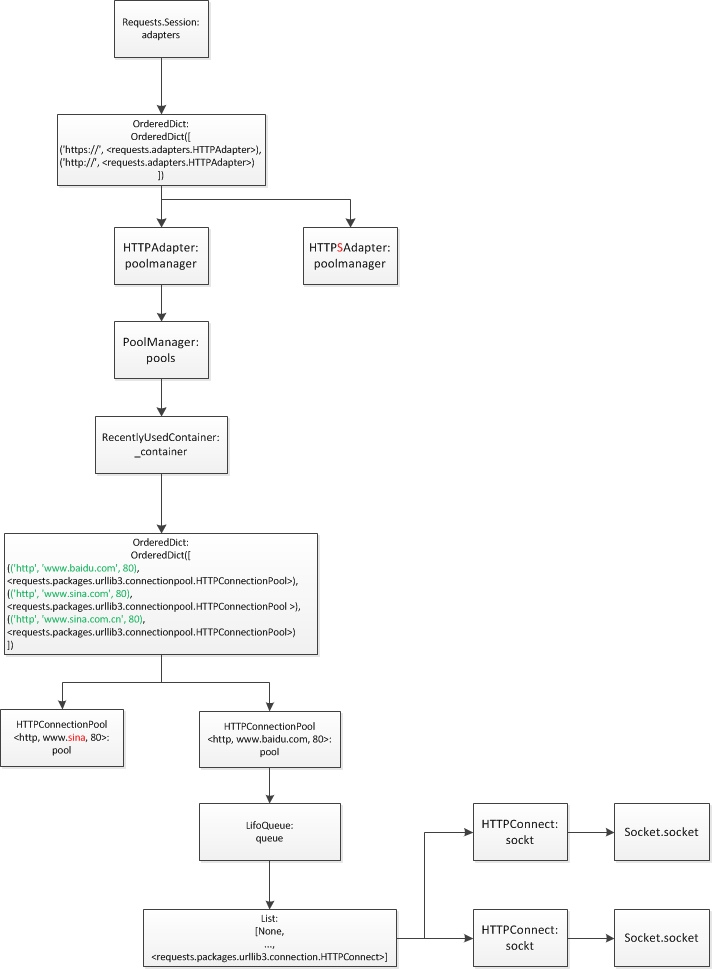
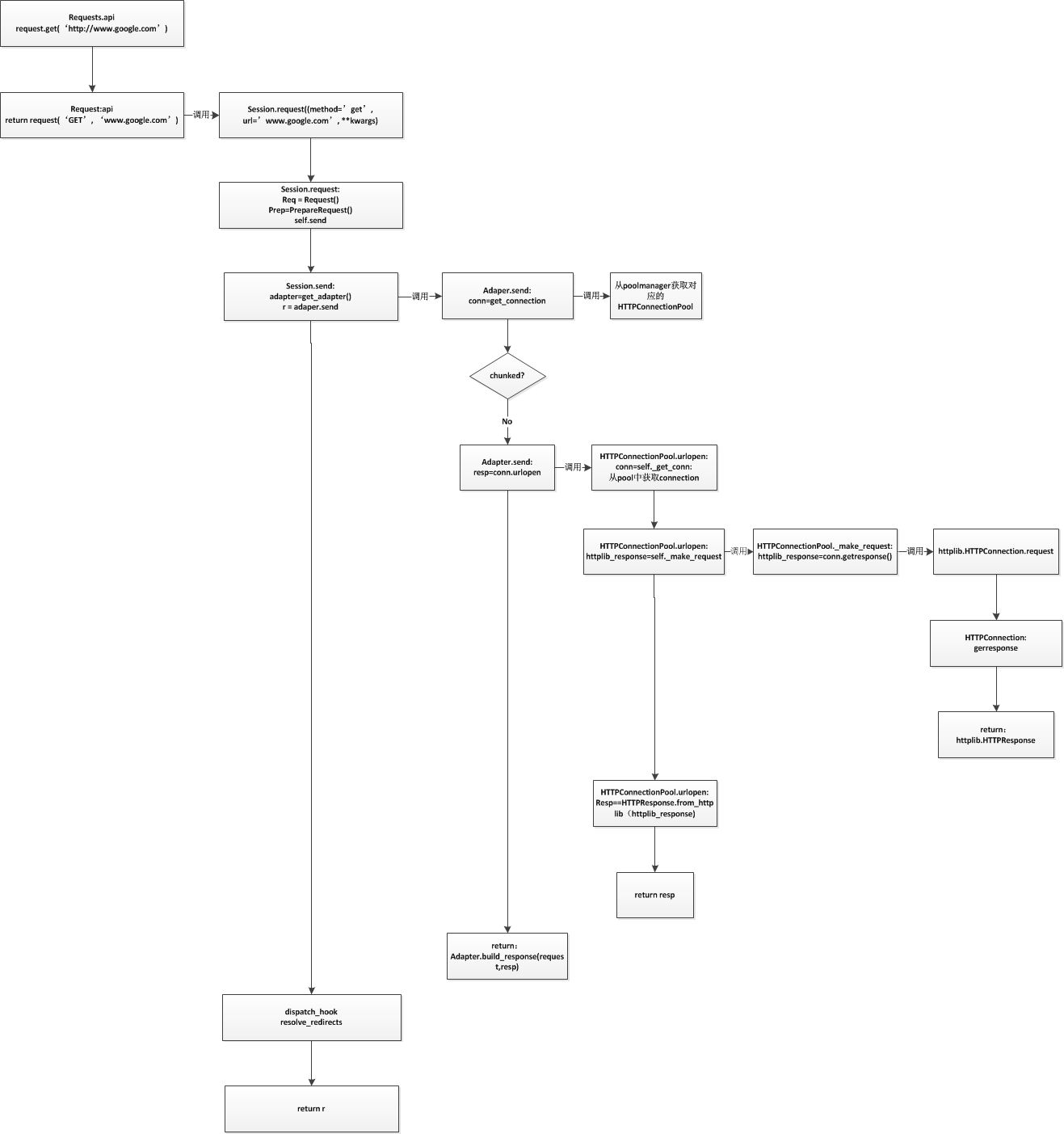
通过之前的流程图知道max_retries参数在HTTPAdapter初始化时设置。可以传递整数或者传递urllib3.util.Retry实例。
|
|
Retry的设计比较简单,在HTTPConnectionPool中根据返回的异常和访问方法,区分是那种链接失败(connect? read?),然后减少对应的值即可。然后再判断是否所有的操作重试都归零,归零则报MaxRetries异常即可。不过对于每次重试之间的间隔使用了一个简单的backoff算法。
|
|
使用重试有几点需要注意:
- 如果使用
requests.get等简单形式,默认会重试3次 - 重试只有在DNS解析错误、链接错误、链接超时等异常是才重试。在比如读取超时、写超时、HTTP协议错误等不会重试
- 使用重试会导致返回的错误为MaxRetriesError,而不是确切的异常。