社区认为大规模部署nova的问题点
OpenStack社区认为大规模部署nova的主要问题在于rabbitmq消息系统和DB数据库的性能瓶颈。因此CellV1和CellV2的主要工作均是拆分消息系统和数据库,使每个Cell拥有单独的rabbitmq和DB系统,然后通过API维护一层映射信息,记录Cell与实例、宿主机的对应关系。
CellV1是多层嵌套概念并且已经被社区抛弃,因此这里主要介绍社区新的扩展方案CellV2.
cellv2的架构
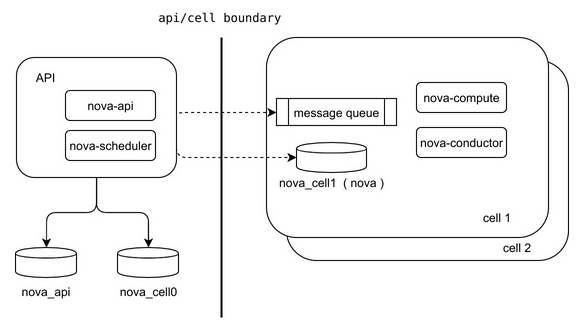
- API层只包含nova-api和nova-scheduler,用于统一处理和调度全局资源。
- API层包含nova_api和nova_cell0两个数据库。其中nova_api库包含所有的全局性资源,例如flavor、quota等;nova_cell0用于存储创建失败后没有被分配到具体host(也就没有从属的Cell)的实例。
- Cell之间是平等的。每个Cell管理自己的各种资源,相互没有从属关系。API与Cell形成扁平结构,理论上Cell可以扩展到多层支持海量宿主机。
nova_api和nova_cell0数据库结构
nova_api的数据库结构如下,只包含全局性的配置、Cell映射以及Instance实例对Cell的对应关系。
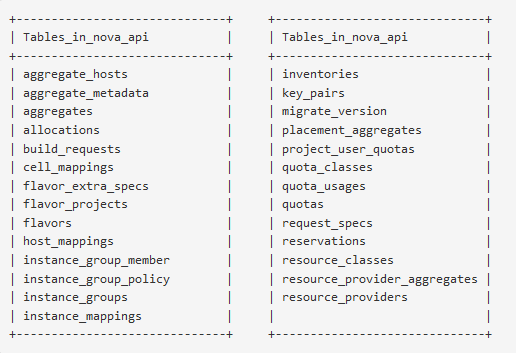
instance_mapping、host_mapping分别存储instance_uuid、host和cell_mapping的对应关系,而cell_mapping存储每个cell的数据库和消息系统连接地址。
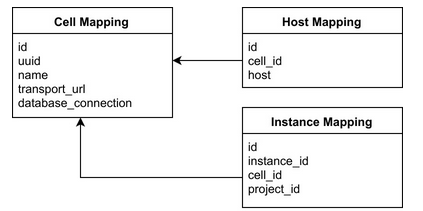
nova_cell0与之前的nova数据库以及各Cell中的数据库相同。主要存储不属于各个Cell的实例信息,可以理解为一个野实例垃圾站。
典型操作的路径
获取instance信息

- nova-api先从instance_mappings表拿到instance的cell_id
- 再从cell_mappings表拿到所在Clll的DB connection
- 直接连接Cell的DB拿到Instance实例的详细信息
重启instance操作
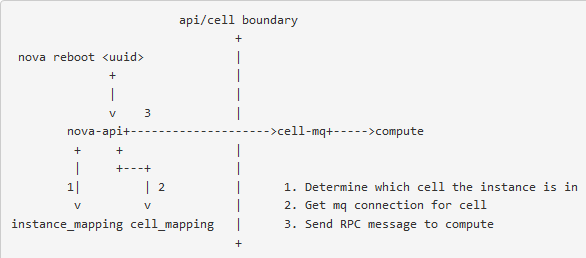
- nova-api先从instance_mappings表里拿到instance所在的cell_id
- 从cell_mappings里拿到所在Cell的
message queue连接 - nova-api直接给mq的相关队列发重启实例的消息
新建instance操作

- nova-api接到用户的请求信息,先转发到nova-scheduler进行调度,nova-scheduler通过placement service, 直接确定分配到哪台机器上
- nova-api把实例的信息存入instance_mappings表
- nova-api把机器信息存到目标Cell的DB中
- nova-api给Cell的
message queue发送消息启动实例
CellV2的缺点
- 每个instance访问需要经过两层数据库,因此需要对cell_mapping、host_mapping和instance_mapping进行合理的缓存,减少数据库的频繁访问。
- 当一个用户的多个实例分布在多个Cell中,获取所有的实例信息比较复杂,需要合理的前端展示策略,例如按照cell的顺序去分页展示。
- 旧版本的消息推送不再适合cellv2架构,因为没有统一的rabbitmq入口了。
CellV2的优点
- 架构清晰简单,只有两层的扁平架构支持多CellV2部署,理论上性能上限只受限于nova_api层数据库。
- 过渡比较顺滑,特别是从不使用Cell升级到使用CellV2比过渡到CellV1简单。
社区的后续发展思路
拆分nova-scheduler,使每层Cell拥有独立的scheduler模块从而对每个Cell定制化调度策略
(完)