容错
A fault-tolerant design enables a system to continue its intended operation, possibly at a reduced level, rather than failing completely, when some part of the system fails. If its operating quality decreases at all, the decrease is proportional to the severity of the failure, as compared to a naively designed system in which even a small failure can cause total breakdown.
维基百科上的容错有几方面意思:
- 容错指系统遭遇故障时不是完全崩溃;
- 容错系统的服务能力能够根据不同程度的故障保证不同程度的服务,优雅降级。
容错与高可用性
容错特指故障发生时的表现;而高可用性是指尽量规避影响用户的可能。可以将一个系统类比成汽车,容错是车祸时自动弹出的气囊,而高可用是刹车系统。我的理解是,容错是高可用性的一个子集,特指(预防)出现问题后的解决方案。
要想打造一个具有高度容错的系统,需要从架构设计、代码、运维、监控等多方面入手,以下介绍一些可以作为容错系统的思考切入点。
重试
重试是错误处理中最常使用的技术,通过重试能够大幅度提高SLA,提高系统的可用性。按照系统的状态,重试的难易程度不同。对于无状态服务,例如大多数HTTP请求,简单重新发起调用即可;但是对于有状态服务,不仅需要被请求方具有幂等性,而是要求整个系统具有幂等性。因为极有可能上次失败的调用,使整个下游的状态都发生了改变。因此,对于不同错误应采用不同的重试策略,一些错误不能重试。
另外,重试有副作用,可能引起大量的重复操作和吞吐。例如,一个页面展示显示不出来,用户会大量频繁点击,反而造成系统瞬时压力过大,给本来处于不正常的系统带来更加重的问题。按照具体策略不同,重试可能需要限制次数,或者根据成功率决定是否重试等。
重试的另外一个副作用是增大了延时,重试时间一般采用退化算法,失败次数越多,下次重试的等待时间越长,那么最大延时取决于最后一次重试成功时的总重试时间,这个时间一定要(远)小于整个系统的延时要求。
超时
对各种请求,特别是跨模块/服务的请求一定要添加超时,无论是同步还是异步请求。超时除了能够保证延时,更大的作用在于能够快速发现问题,从而积极采取应对策略。假设一个系统出现内部问题,请求被开在某个状态无法返回,那么这个问题就很难处理,一方面监控发现需要一定时间,另一方面即使发现也很难处理,因为卡的状态可能是复杂且未知的。
限流
限流是拒绝一部分请求而保障另一部分请求,简单来说就是削峰填谷。根据具体应用一般有两种方式,一种是缓存请求排队,需要考虑最后排队的请求也要在一定延时内返回。另外一种方式直接限制QPS,在请求过高时直接拒接掉,具体算法也有两种,令牌桶和漏桶算法。在实际使用时可以两种方式结合使用,在保证延时的情况下将请求排队,将不能保证延时的那部分请求直接拒绝。
HA
这里的HA特指一些集群的方案和算法,保证单个服务或者单台机器出现问题而整个系统正常提供服务。简单来说就是避免单点问题。这个比较有名的总结即为下图。

通过改图可以总结出,就是简单的方案性能高,但是可用性较低;而复杂的方案,影响吞吐和延时。
从系统内部和外部可以将集群HA方案分为两个维度:
- 集群本身支持HA,通过各种一致性算法保证强一致或者最终一致
- 集群外部,例如通过使用prox、LB等各种代理,但这要求服务最好无状态
服务分离
将重要服务/客户分离是减小问题的影响范围的最简易手段。现在比较流行微服务架构,不同的服务通过松耦合的方式连接,不同服务往往部署在不同的docker、虚拟机或者物理机上。根据服务的重要性不同,可以分离的程度不同。一些及其重要的服务,甚至单独部署在隔离的物理机上。
服务冗余
这里的服务冗余与HA不同,更加偏向于上图中的Backups。平时不提供服务,专门存在一个备份系统在主系统出现问题时进行快速切换。这里有两个问题,一个是数据的一致性问题,可以时时同步或者冷备份,但是一般都有一定时间内的数据丢失问题。而且在实际使用过程中,备份的系统往往有时候并不处在可用状态。主系统可能定时升级,而备份系统没有;同步到备份系统的数据可能某次有丢失不全等等。亚马逊也出现过类似问题,出现故障时恢复耗时过长,而主要原因就是备份系统起不来数据也不全。备份冗余的另外一个问题是快速切换,如果切换太慢那么可能还不如修复主系统。鉴于实际的种种问题,一般出现故障不太会倾向于切换到备系统,坑比较深。
服务降级
当出现故障后,能够按照故障的严重程度不同,提供不同质量的服务。服务降级是容灾的核心,但是往往很难做到,这不仅需要好的架构设计,也需要好的编程实现。比较容易理解的例子是页面渲染,例如在页面不能加载一些宣传语广告时直接跳过,保证主要功能可用。另外通过将系统做到跨机器、跨机柜、跨TOR、跨机房、跨地域的容灾设计,可以保证不同程度的服务可用性。
downtime
对于各种可能出现的宕机,Oracle有一个概述,可以针对提到的这些点对当前系统进行重点排查。
非计划宕机
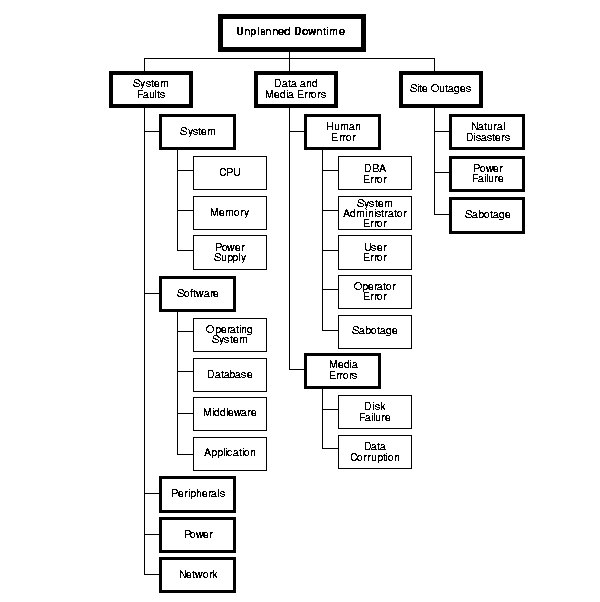
有计划宕机
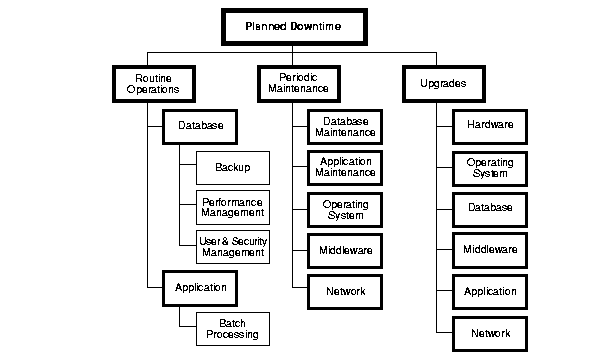
除了针对这些点进行设计,更重要的是要有定期排查(演练)。现实是往往有一些容错、容灾、备份方案,但是经过一段时间没有用上,这些手段就再也不演练。当真的出现问题时,这些手段已经跟当前系统不配套,失效了。
(完)