RabbitMQ架构
RabbitMQ的架构和时序图,RabbitMQ、AMQP、RabbitMQ网络框架
set与List对象相似,均为可变异构容器。但是其实现却和Dict类似,均为哈希表。具体的数据结构代码如下。
|
|
setentry是哈希表中的元素,记录插入元素的哈希值以及对应的Python对象。PySetObject是哈希表的具体结构:
fill 被填充的键的个数,包括Active和dummy,稍后解释具体意思used 被填充的键中有效的个数,即集合中的元素个数mask 哈希表的长度的掩码,数值为容量值减一table 存放元素的数组的指针smalltable 默认的存放元素的数组当元素较少时,所有元素只存放在smalltable数组中,此时table指向smalltable。当元素增多,会从新分配内存存放所有的元素,此时smalltable没有用,table指向新分配的内存。
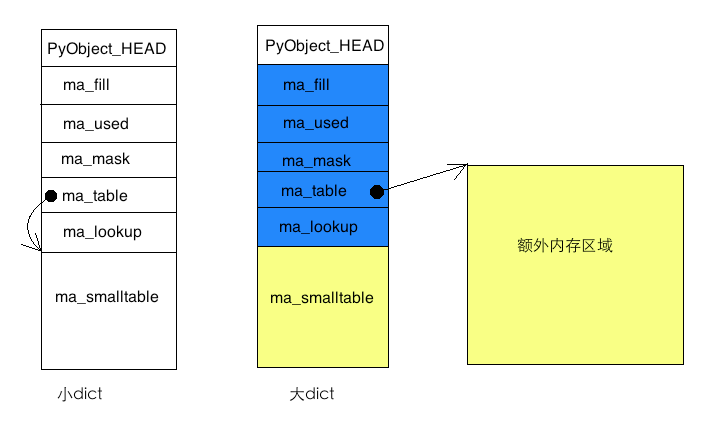
哈希表中的元素有三种状态:
dummy是为了表明当前位置存放过元素,需要继续查找。假设a和b元素具有相同的哈希值,所以b只能放在冲撞函数指向的第二个位置。先删除a,再去查找b。如果a被设置为NULL,那么无法确定b是不存在还是应该继续探查第二个位置,所以a只能被设置为dummy。查找b的过程中,第一个位置为dummy所以继续探查,直到找到b;或者直到NULL,证明b确实不存在。
set中会存在缓存系统,缓存数量为80个_setobject结构。
|
|
freelist缓存只会对_setobject结构本身起效,会释放掉额外分配的存储键的内存。
set中元素查找有两个函数,在默认情况下的查找函数为set_lookkey_string。当发现查找的元素不是string类型时,会将对应的lookup函数设置为set_lookkey,然后调用该函数。
|
|
查找函数最后返回的插槽有三种情况:
set_lookkey与此类似,只不过比较元素时需要调用对应的比较函数。
为了减少哈希冲撞,当哈希表中的元素数量太多时需要扩大桶的长度以减少冲撞。Python中当填充的元素大于总的2/3时开始重新散列,会重新分配一个有效元素个数的两倍或者四倍的新的散列表。
|
|
(完)
本篇的信号处理机制不是指Python的signal模块的使用,而是指Python解释器本身如何处理信号以及如何实现signal模块。Python解释器处理信号机制需要做好两件事情:

大体上,Python解释器对信号的实现总体思路比较简单。Python解释器对信号做一层封装,在这层封装中处理信号,以及信号发生时的回调函数,使之能够纳入整个Python虚拟机的运行中。我们先从信号的初始化开始一点点揭露整个运作机制。
信号机制的初始化是在Python初始化整个解释器时开始的,Python在初始化函数中调用initsigs来进行整个系统以及singal模块的初始化。
|
|
直接进入到singalmodule.c中看signal模块以及信号的初始化。
|
|
可以看到Python将用户自定义信号处理函数保存在Handler数组中,而实际上向系统注册signal_handler函数。这个signal_handler函数成为信号发生时沟通Python解释器和用户自定义信号处理函数的桥梁。可以从signal.signal的实现中清楚的看到这一点。
|
|
当信号产生时,操作系统会调用Python解释器注册的信号处理函数,即上文中的signal_handler函数。这个函数将对应的Handler结构中的信号产生标志tripped设置为1,然后将一个统一信号处理函数trip_signal作为pending_call注册到Python虚拟机的执行栈中。于是,Python在虚拟机执行过程中调用pending_call并执行各个用户自定义的信号处理函数。
|
|
这里面的PyErr_CheckSignals函数也会被其他模块调用直接信号的处理。例如,在file.read读取文件过程中中断,Python对调用该函数进行信号处理。至此,可以看到整个信号处理的流程:
signal_handler,并将用户自定义信号处理函数设置到对应的Handler数组中signal_handler设置tripped=1,然后调用trip_signal将统一处理函数checksignals_witharg作为pendingcall注册到Python虚拟机的执行栈中。pendingcall时调用checksignals_withargs,从而信号处理函数得以执行。PyErr_CheckSignals进行信号处理。通过注释以及代码剖析可以归纳Python的信号语义:
signal_handler中会再次注册信号处理函数)
|
|
|
|
|
|
|
|
t.join一直阻塞,因此在子线程没有退出前不能处理信号。(C语言的信号处理是可以打断堵塞信号的)Python的信号语义与Linux的C语言的信号语义有一些不同。
(完)
Python的字符串对象是一个不可变对象,任何改变字符串字面值的操作都是重新创建一个新的字符串。
|
|
字符串对象在Python中用PyStringObject表示,扩展定义后如下。
|
|
ob_type字符串的类型指针,实际指向PyString_Type
ob_size保存的是字符串的实际长度,也是通过len(s)返回的长度值。而字符串实际占用的内存是ob_size + 1,因为C语言中需要额外的NULL作为字符串结束标识符。
ob_sval是实际存储字符串的内存,分配时会请求sizeof(PyStringObject)+size的内存,这样以ob_sval开始的内存长度就是size + 1的长度,正好用来存放以NULL结尾的字符串。
ob_shash是字符串的hash值,当字符串用来比较或者作为key时可以加速查找速度,默认值为-1。
|
|
ob_sstate记录字符串对象的状态。字符串可能有三种状态:
|
|
字符串对象是不可变对象,因此相同的字面值的变量可以绑定到相同的字符串对象上,这样减少了字符串对象的创建次数。这样的行为称为interned。默认情况下空字符串和单字符字符串会被interned。
|
|
另外一些情况下,例如__dict__、模块名字等预计会被大量重复使用或者永久使用的字符串,在创建时也会调用PyString_InternInPlace进行interned操作。
|
|
当字符串的引用计数为零时会被回收。
|
|
可以通过字符串对象的类的结构中找到对象的操作函数。
|
|
tp_base被赋值为PyBaseString_Type,因此字符串对象是basestring的子类。
(完)
整数对象是固定大小的Python对象,内部只有一个ob_ival保存实际的整数值。
|
|
为了最大限度的减少内存分配和垃圾回收,Python对整数对象设计了缓存。整数对象的缓存由两种类别构成:
在Python启动时会创建一批默认值为[5, 257)的小整数对象,存储在small_ints中。这些整数对象的生命周期为Python的生命周期,不会被回收。Python只所以这样处理是因此解释器内部会频繁用到这些小整数,如果每次都分配-回收-再分配显然效率不高,不如创建后一直保留用空间换时间。
|
|
可以通过id命令查看小整数对象的特性。
|
|
通过上面的例子我们可以知道,其他整数对象使用的内存是不固定的,申请时分配释放时回收。当然,这个回收并不一定是返还给系统内存,整数对象系统本身会缓存一部分整数对象。下面通过整数对象系统的初始化揭露整数的缓存方案。
当Python初始化时会调用_PyInt_Init函数进行整数的初始化。
|
|
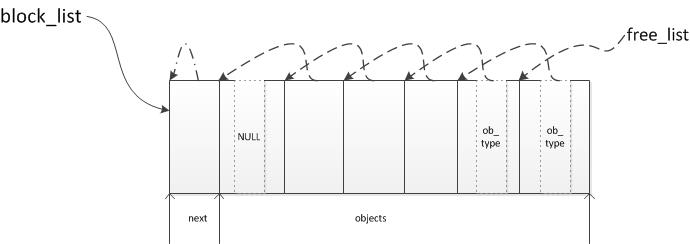
缓存会用到数据结构PyIntBlock以及block_list和free_list链表。PyInBlock用来一次申请多个整数对象的内存,然后再一个个用作PyIntObject,并且通过域next链接到block_list链表上。free_list中是空闲的PyIntObject的链表。fill_free_list初始化后的内存结构如下。
然后通过_PyInt_init初始化为小整数,并将其指针存储到samll_ints数组中加快查找。_PyInt_init初始化后的内存结构如下。
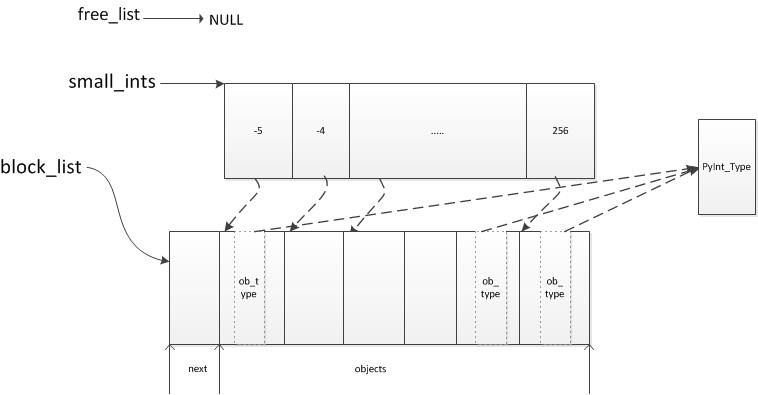
我们可以看到整数对象通过PyIntBlock和free_list进行内存申请和缓存的。
当新创建一个整数对象时,先从free_list中查找空闲的整数对象,如果有则直接使用;否则会重新分配PyIntBlock结构并进行初始化。
|
|
创建一个新的整数257之后的数据结构:
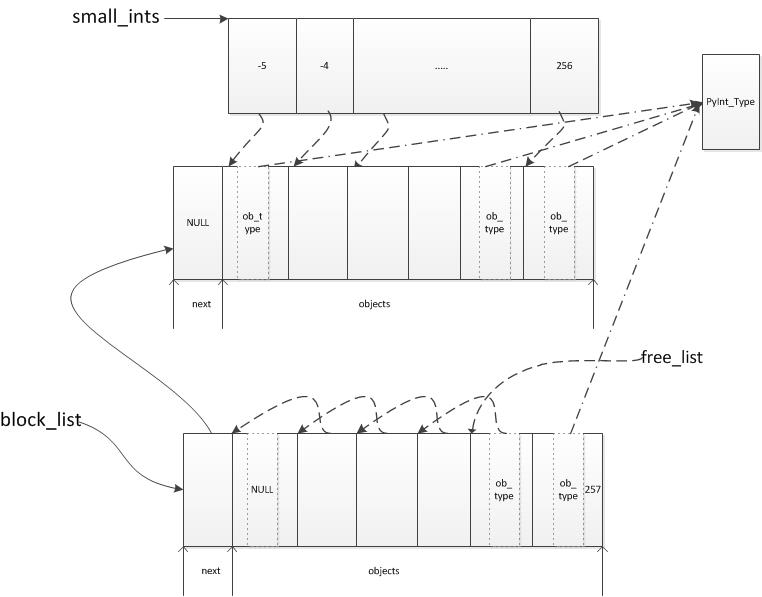
当整数对象的引用计数归零时则对其进行回收,由函数int_free操作
|
|
可以看到被回收的整数对象被连接到free_list链表中。这里有个问题,整数对象的内存什么时候才真正释放呢?
原来整数对象的真正释放是在最高代的GC中进行,当GC运行时会调用PyInt_ClearFreeList进行整数对象内存的释放PyInt_ClearFreeList对整个block_list进行遍历,如果其中所有的整数对象的引用计数都为零,则释放整个block。可见整数对象的内存是以PyIntBlock为单位申请和释放的。
|
|
整数对象定义了许多操作符,可以通过以下代码自行查看。
|
|
|
|
Python中的垃圾回收机制基于引用计数(ob_refcnt),因此需要解决循环引用导致引用计数不能归零的问题。例如
|
|
虽然list1与list2已经成为需要回收的垃圾,但是由于相互引用导致引用计数不能归零,从而不能触发自动回收。因此Python引入了循环垃圾收集器。
判断对象是否为垃圾的逻辑比较直白,有外部引用或者被有外部引用的对象引用的对象为非垃圾对象;否则为垃圾对象。具体过程为,遍历所有对象将对象中引用的元素(其他对象)的引用计数减一,最后引用计数不归零的对象(存在外部引用)不是垃圾对象;被不是垃圾对象引用的元素(其他对象)也不是垃圾对象;剩余的则为垃圾对象。可以归纳为如下步骤:
再次遍历:
<1> 处理对象:对该对象进行标记
所有引用计数为零的对象没有外部引用,标记为可能是垃圾;
所有引用计数不为零的对象存在外部引用,必然不是垃圾。
|0 |可能是垃圾 |list1、list2、list3、list5|
|>0 |不是垃圾 |list4、list6|
<2> 处理对象:遍历不是垃圾对象中的元素,不是垃圾对象中的元素必然不是垃圾
这部分处理代码比较复杂,每个对象可能作为两种角色进行处理。作为代中的对象以及作为对象中的引用元素。如果作为元素被处理,则肯定不是垃圾。
各个阶段对象中的引用计数
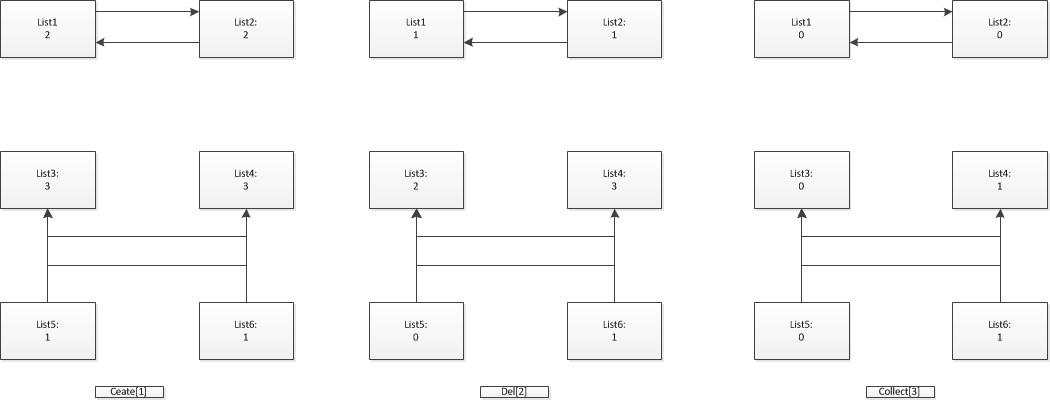
垃圾对象不一定能被自动回收。所以上面的步骤只能确定垃圾对象,然后对垃圾对象进行额外处理甄别不能回收和能被回收的部分。
一些基本对象不会产生循环引用,例如int、float、string等,所以没有必须使用循环垃圾收集器,基本的引用计数回收机制即可。还有一些容器类对象,他们中的元素都是基本元素不会引起循环引用,例如{‘a’:1}、(1, 2, 3),因此也不纳入循环垃圾收集器。所以只有部分容器类对象、生成器、含__del__类等才纳入循环垃圾收集器。
如上分析,整个循环垃圾收集的效率严重依赖可能引起循环引用的对象的个数。为了减少垃圾回收的动作,Python将对象分代:存活越长的对象越不可能是垃圾,就减少对其进行垃圾回收的次数。那么存活的时间长短就用经过了几次垃圾回收来判断,于是刚创建的对象为一代,当经过一次垃圾回收还存活的对象放入二代;多次一代垃圾回收后,才进行一次二代垃圾回收。Python将整个对象分为三代,当分配足够数量的对象后(700)进行一次一代回收;当进行一定数量(10)一代回收后进行二代回收;同理进行三代回收。
|
|
(图片来自: https://nodefe.com/implement-of-pymalloc-from-source/)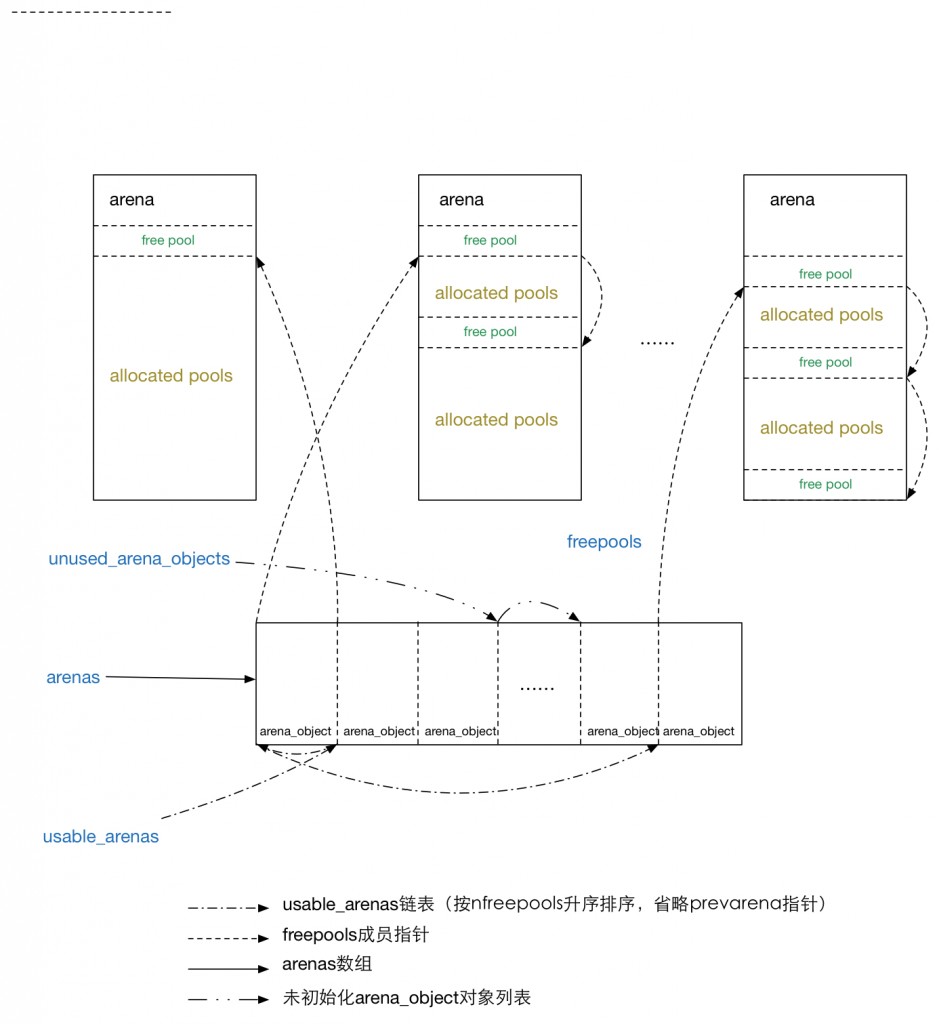
Python的对象分配器将内存分为三个维度,从大到小叫做arena、pool以及blcok。
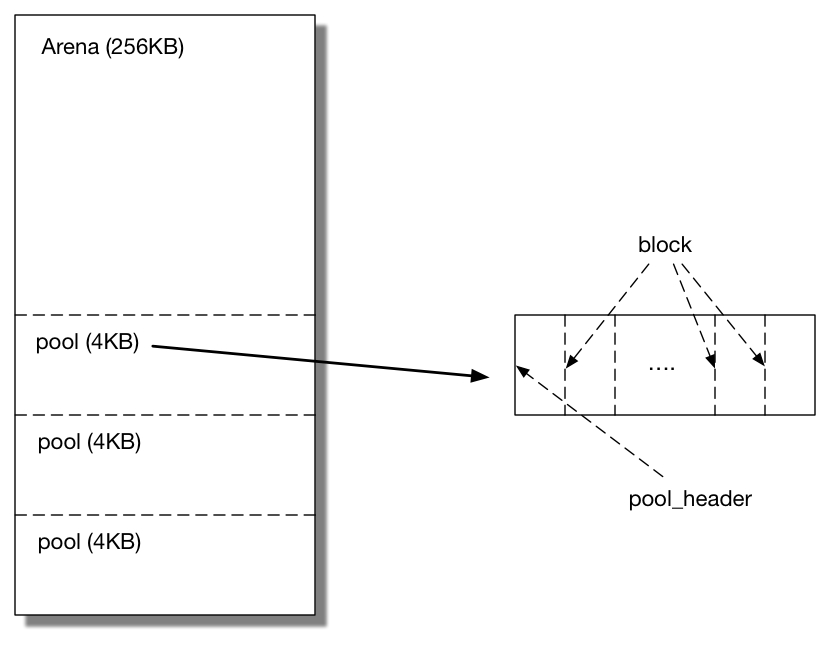
一个arena分为两个部分。管理部分arena_object,每次需要创建一个arena时,先创建一个arena_object结构放入arenas数组。然后再申请256KB内存作为arena管理的内存部分。arena_object和arena的内存是分开的,通过域address标记。
将arena的内存按照4KB再划分则为一个个pool。每个pool也分为两部分,内存的高端为pool_header用于管理分配出去的block、回收的block以及从来没有被分配出去的block;剩余的内存作为另一部分再被分为一个个block。每个pool一旦使用只能分配固定个数的block。pool的两部分在同一个连续的页内。
pool会有三种状态:
used: 部分block被分配出去,另一部分还未被分配出去。该状态的pool会被放入usedpools中以加快搜寻可用pool的速度。如果used的pool中的最后的block也被分配出去则pool进入full状态,并且从usedpool中去掉。如果used的pool中的block全被回收则pool进入empty状态,并且从usedpool中去掉放入arena中的freepools链表中。
empy: 所有的block都没有被分配出去。有两种可能,一种是pool中的block都被回收了,从used状态转变而来,这样的pool放入arena的freepools链表中;另外一种是随着arena初始化而来,此时还没有作为pool存在,只是作为arena中没有被使用的内存部分。
full: 所有的block被分配出去了。不存在任何链表中,当有block被回收时进入used状态再放入usedpool中。
block是内存管理的最小单位,每次分配需要按照block对齐。每次分配和回收都是固定个数的block。当内存被回收时,所有的内存会放入pool中的链表freeblocks中。没有被分配出去的block存在两个地方,一部分从来没有被分配出去过,通过nextofset表明空闲的block的起始地址;另一部分是分配出去又被回收,会被放入freeblocks中。
被回收的block会将头部作为指针链接下一个被回收的block
|
|
按照每次可以分配的block的个数,pool被分为几种类型(block size),同时也是其在usedpool中的序号(szidx)。每页为4KB,每个8个block1算作一组,所以pool最多有64个类型。具体可以参见下面代码注释。
Objects/obmalloc.c
|
|
用户可以通过Session.request接口传入auth参数指定用户名和密码。auth参数可以是(username, password)的数组;也可以是HTTPBaiscAuth类似的实例,只要支持调用即可。
|
|
认证信息主要从多个方面来获取
requests也支持.netrc,.netrc用于记录访问的认证信息,具体的语法可以参考这里,大致语法如下。
认证信息
|
|
定义ftp bash登录后的执行命令
|
|
当访问www.sina.com时,会发现requests中缓存了两个地址www.sina.com与www.sina.com.cn,因为前一个地址会被重定向到后一个地址上。当我们用curl工具直接访问会发现,该地址返回了301 Moved Permanently以及Location: http://www.sina.com.cn。于是requests会自动对重定向地址再次发起请求。
|
|
重定向后的访问逻辑主要在SessionRedirectMixin中(具体的请求过程分析参见这里)
|
|
|
|
一般情况下只有指定的方法能够重定向
|
|
根据重定向返回的状态码和访问方法,对重定向地址的访问需要修改访问方法
|
|
如果简单的使用requests,会发现(requesets.get..)使用了默认参数的HTTPAdapter,因此所有由HTTPAdapter初始化参数指定的功能都没有办法使用,例如:重试、缓存池大小、缓存连接池大小、缓存池是否堵塞等。当然,因为requests.get方式只会发起一次HTTP请求,所以缓存相关的都没有设置的必要。
|
|
超时时间可以通过timeout参数指定,可以详细为(connect_timeout, read_timeout)。
|
|
通过流程图可以看到,传递的timeout参数一直进入到HTTPAdapter.send内。
|
|
然后实例化后的timeout传递给HTTPConnectionPool,其中的connect_timeout设置为conn.timeout然后一直传递到socket中,通过socket.settimeout设置起效。需要注意socket是在设置参数之后再执行的bind->connect操作。
|
|
其中的read_timeout在HTTPConnectionPool中设置。通过代码可以看到socket.settimeout设置的是socket所有操作的超时时间,在不同的阶段调用该函数就设置了接下来操作的超时时间,settimeout -> bind -> connect -> settimeout -> read。
|
|